
Building NLP Pipelines with Haystack
Insights from a User on Development, Documentation and Experimental Features


The end of 2024 brought an unexpected opportunity when I discovered the "Advent of Haystack" event. Haystack is an open-source framework for building production-ready LLM applications, retrieval-augmented generation (RAG) pipelines, and state-of-the-art search systems that work intelligently over large document collections, created by deepset, a Berlin-based enterprise software company. Having worked extensively with NLP systems, I was immediately drawn to this series of ten coding challenges. Each task promised to explore different aspects of building intelligent document processing pipelines with Haystack 2.x.
Evolution from Haystack 1.x to 2.x
Having previous experience with Haystack 1.x made the transition to version 2.x particularly interesting. The framework's evolution in supporting modern RAG applications and its enhanced capabilities for building intelligent agents with LLMs showed significant improvements. The modular design remained a core strength, but the new version brought more sophisticated options for document understanding and information retrieval.
The journey began with fundamental document retrieval tasks, gradually progressing to more sophisticated implementations. Early challenges focused on setting up basic RAG pipelines and integrating vector databases. As the complexity increased, I found myself working with audio processing through AssemblyAI and optimizing inference using NVIDIA NIMs. The most engaging aspects came from building self-reflecting recommendation agents and inventory management systems. Working with MongoDB for vector search and implementing multi-query RAG systems pushed my understanding of what's possible with modern NLP architectures. The final challenges on evaluation methodologies were particularly valuable, providing concrete ways to measure and optimize pipeline performance.
While building various pipelines and experimenting with different approaches, I gained hands-on experience with the Haystack 2.x environment and its toolboxes wrapped around it. Each tool served distinct purposes in the development process, from rapid prototyping to implementing advanced features. The following three products particularly caught my attention as they each addressed different aspects of the development workflow, each with both strengths and areas for potential improvement.
Haystack Documentation
The documentation emerged as a crucial resource, especially when working with unfamiliar components. What stood out was how the documentation maintained clarity even when explaining complex concepts like pipeline architectures and component interactions. I particularly appreciated the practical examples that accompanied technical explanations, making it straightforward to adapt solutions for the challenges. The well-organized structure helped quickly locate specific information about pipeline components and their configurations.
🚅 Components
- fetcher: LinkContentFetcher
- converter: HTMLToDocument
- splitter: DocumentSplitter
- ranker: TransformersSimilarityRanker
- prompt_builder: PromptBuilder
- generator: HuggingFaceLocalGenerator
🛤️ Connections
- fetcher.streams -> converter.sources (List[ByteStream])
- converter.documents -> splitter.documents (List[Document])
- splitter.documents -> ranker.documents (List[Document])
- ranker.documents -> prompt_builder.documents (List[Document])
- prompt_builder.prompt -> generator.prompt (str)The Haystack documentation stood out with several well-implemented features that enhanced the learning and development experience:
Version navigation offered clear distinction between Haystack 1.x and 2.x, with a prominent selector that made it easy to reference the correct documentation for each version
The search functionality excelled at finding specific components and concepts quickly, with real-time suggestions and relevant results across different documentation sections
The left sidebar navigation provided an intuitive hierarchy of topics, logically organizing content from basic concepts to advanced pipeline components and optimization techniques
Code examples were particularly helpful with:
Consistent syntax highlighting that improved readability
Copy-paste functionality for quick implementation
Complete working examples that could be run immediately
The step-by-step tutorials included practical explanations of common use cases, making it easier to understand how different components work together in real-world scenarios
API reference documentation maintained a consistent structure across all components, making it simple to find specific parameters and usage examples when needed
Nevertheless, from my point of view, the Haystack documentation could benefit from some enhancements to make it even more user-friendly:
Combining different concepts often requires piecing together information from multiple documentation sections, which could be streamlined
More real-world examples showing how to integrate various components would help bridge the gap between theory and practice
Sample code would benefit from more detailed inline comments explaining the purpose of each code section
The relationship between component inputs and outputs could be more clearly visualized in the documentation; Especially required input parameters and expected output formats could be presented more clearly, similar to scikit-learn's documentation style, e.g. for pipelines.
Valid connection patterns between components could be better highlighted to prevent trial-and-error development
When having built a pipeline, it would be really helpful to have a text-based parameter documentation generator that lists all required and optional inputs for the entire pipeline, making it easier to understand what needs to be provided to which component(s) of the pipeline.
A chat interface for documentation assistance would be the "cherry on the cake" - enabling quick Q&A about specific features, helping locate relevant documentation sections, and providing tailored code examples for specific use cases
deepset Studio
The cloud-based development environment streamlined initial pipeline creation through its visual interface. Its ability to visually connect components and validate pipeline structures streamlined the development process. The built-in vector database options and pre-built pipeline templates for common use cases like RAG made prototyping significantly faster. Most notably, the ability to test pipelines in the Playground and export them as YAML or Python code provided excellent flexibility.
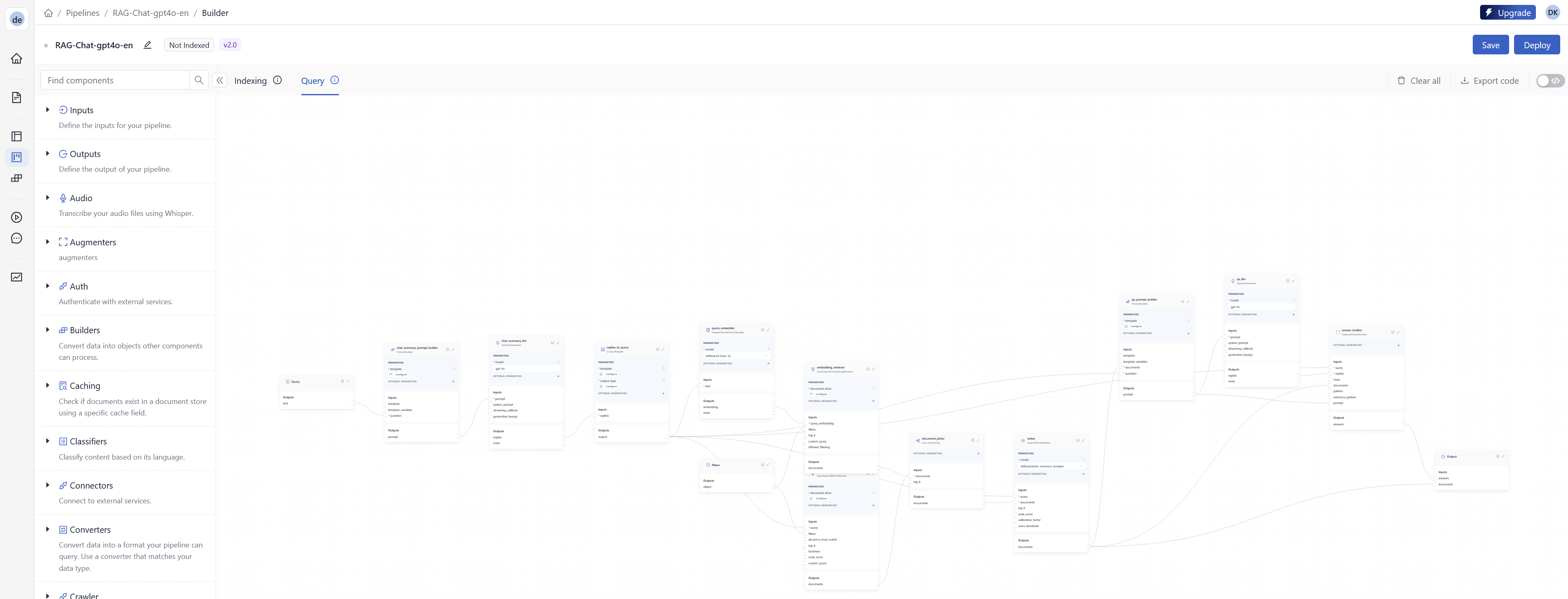
The experience with deepset Studio revealed several standout features that enhanced the development workflow:
Intuitive drag-and-drop interface made pipeline construction straightforward and efficient
Visual representation helped understand pipeline flow and component relationships at a glance; Easy swapping of components allowed quick experimentation with different pipeline approaches
Clear visualization of component connections simplified understanding of complex pipeline architectures
Component configuration through forms reduced setup time and prevented syntax errors
Immediate testing capability in the playground without requiring local setup
Seamless transition from visual design to code export for production use; No installation required for initial experimentation and testing of pipeline concepts
While deepset Studio offers a powerful visual development environment, there are several areas where it could become even more user-friendly:
Setting up environment variables can be challenging for non-technical users - could benefit from guided configuration wizards, direct integrations, and interactive setup tutorials
Current monochrome connections make complex pipelines harder to follow - color-coded connections based on data types, input-output matching, different line styles, and visual flow indicators would improve readability
Real-time validation could be enhanced with dynamic suggestions for compatible connections, visual indicators for valid combinations, and auto-completion for parameters
Deployment process could be more robust with pre-deployment checks, preview options, one-click rollback capability, and status monitoring
Missing bidirectional workflow between code and visual interface - ability to import existing Python/YAML pipelines, visualize them automatically, edit visually, and re-export as updated code
Warning messages for potentially problematic configurations could prevent issues before deployment
“haystack-experimental” Package
Working with the experimental features package of Haystack during the challenges revealed promising new features for building advanced AI agents and specialized pipeline components. The package provided access to cutting-edge functionalities not yet available in the main release, particularly useful for implementing self-reflecting agents and custom tool integration. While these features required more careful handling due to their experimental nature, they offered exciting glimpses into future capabilities.
The experimental features in Haystack provided exciting insights into upcoming capabilities and development direction:
Early access to cutting-edge features showed promising new approaches to pipeline construction and agent capabilities, all while maintaining impressive stability in practical use
Active community involvement enabled direct feedback on feature implementation, helping shape the framework's development direction before features reach the core package
Hands-on experience with emerging NLP techniques and innovative components provided valuable insights into Haystack's technical evolution
Surprisingly robust implementation allowed testing experimental features in real-world scenarios despite their development status
Well-designed integration with existing core components made it easy to combine established and experimental features in production pipelines
While the experimental features showed impressive stability, there are some areas where the experience could be enhanced:
Documentation for experimental features needs more depth, including variables, detailed usage examples, edge cases, and clear indication of production-readiness status
Version management could be improved with better communication about breaking changes and detailed changelogs for experimental features
A clear roadmap showing planned feature progression and timelines for integration into the core package would help with project planning
More comprehensive examples demonstrating how experimental features interact with core components and each other
Better visibility of known limitations, potential workarounds, and feature maturity levels
Conclusion
The Advent of Haystack event provided valuable insights into the framework's capabilities and its evolving ecosystem. Through hands-on experience with deepset Studio, comprehensive documentation, and experimental features, it became clear that Haystack is maturing into a robust platform for building sophisticated NLP solutions. The combination of stable core functionality with innovative experimental features creates an exciting environment for development. Building NLP pipelines with Haystack proved particularly enjoyable, with the pipeline’s graph visualization feature and deepset Studio's graphical interface making it remarkably clear how components connect and how to be debugged. These visual aids were invaluable for understanding and validating the flow of data between components, significantly reducing the complexity of pipeline construction. The opportunity to work with partner services from Weaviate, AssemblyAI, NVIDIA, Arize, and MongoDB added another valuable dimension to the learning experience, providing hands-on exposure to industry-standard tools and their integration capabilities.
While there's room for improvement in areas like documentation detail and UI workflows, especially for users without a technical background, the overall experience demonstrated the framework's strength in bridging the gap between prototyping and production-ready systems. As Haystack continues to evolve, its commitment to balancing innovation with stability makes it a promising choice for developers working on complex document processing and information retrieval tasks.